“You have to break a few eggs to make an omelet.”
It’s an interesting proverb, with an even more interesting (and dark!) history. Your parents were always ready to trot it out, to apply it to situations in your life. A shorter-term cost creates a longer-term gain, so keep pulling those weeds.
In a way, the proverb applies to virtualization. We simulate other systems with software. This can create a performance cost, but don’t worry … the benefits are real and compelling.
With server virtualization, it’s easier to understand these cost-benefit propositions. These environments are everywhere now, we see the increased utilization of multicore server architectures, and we see management workflows made more efficient and more powerful.
With storage virtualization, it can be harder to see these cost-benefit propositions. It starts with the thing we’re virtualizing. It’s either a (seemingly) dumb device, or it’s an expensive intelligent storage system. In either case, why would I virtualize such a thing?
There are compelling benefits in storage virtualization, including some that aren’t so obvious. It can become easier to accept them, when it’s easier to see them.
So, why is virtualization a good thing?
Because we said so?
On our website’s storage virtualization page, you’ll find the typical language found on other vendor pages, stating the various benefits of storage virtualization:
- Reduce costs
- Improve reliability
- Improve performance
- Improve agility and ability to scale
These are assertions, and they may leave readers with questions. What cost am I paying? What benefits are obtained, and how?
Let’s break some perfectly good eggs
Broadly, virtualization is an extra layer of software. There are different ways to construct this layer. Jon Toigo wrote about in-band versus out-of-band methods, but in the end they are all extra layers that must be traversed in the data path.
By introducing a storage virtualization layer, we’ve taken devices that read and write and we’ve wrapped them up in software that simulates devices that read and write. It seems like running to stand still. Why would we do that?
Where’s our omelet?
The benefit here is that we’ve created a place in the data path for powerful general-purpose computers to run software. This creates enormous potential for value, including the points we repeat from above:
- Reduce costs
- Improve reliability
- Improve performance
- Improve agility and ability to scale
To see how these benefits are realized, let’s zoom in on the virtualization.
Points for good behavior
The way applications interact with storage is sometimes called the access method. The access method can be modeled as an application programming interface, or API. The API defines the expected behavior, and it gives us a convenient framework for virtualization.
Block storage is an access method, and the SCSI Architecture Model (SAM) defines this “Execute Command remote procedure”:

Reduce costs
First, we can represent blocks full of zeroes with … nothing at all! Blocks of zeroes don’t need to be stored—that’s a common thin provisioning method. Thin provisioning makes capacity planning easier. It increases utilization of the underlying capacity, to reduce costs. Take that idea a step further, and you get deduplication, where duplicate ranges of block data are hashed down to single instances in the storage pool.
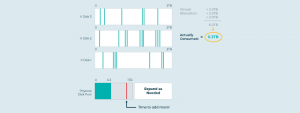
We can monitor access patterns to virtual blocks, synthesize a “temperature” for each block, and then arrange them within a storage pool so that hot data goes on fast, expensive equipment and cold data goes on slow, cheap equipment or cloud. This auto-tiering feature arranges data within virtual disks, so that applications see the data they want, while the virtualization system optimizes for cost and performance dynamically and automatically. This further reduces cost, even while improving performance. More on that below.
Improve reliability
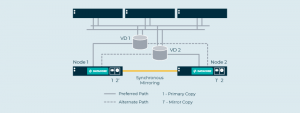
Data blocks can be stored in two or more places, across hardware platforms, to create high availability and to guard against points of failure.
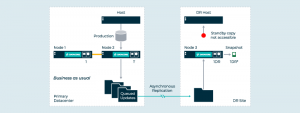
Data blocks can be shot across the Internet for disaster preparedness.
Improve agility and ability to scale
Virtual disks remain logically constant, while data blocks are being moved underneath, automatically. This makes it easy to perform migrations. Bring in a new storage system, connect it to the back end of the storage virtualization software, and data migrates automatically and seamlessly to the new storage system.
Need to scale horizontally? Add more nodes to perform the storage virtualization, to create an N+1 architecture. Move the virtual disks among these nodes, similar in concept to live migration of virtual machines, to rebalance the load.
Improve performance
Surely all this extra processing and complexity increases latency and reduces throughput? Not necessarily, and that’s perhaps even more interesting than all those data services.
How could this be? Recall that the system can play games. Think big. Realize that you have a modern multicore server platform full of high-speed RAM and dozens of parallel CPUs.
Cache hot data in RAM. Use remote synchronous mirroring to protect the RAM caches from individual failures. Process I/O requests in parallel on as many CPUs as possible. Hook all those chickens up to the plow! Keep every transistor busy in your virtualization implementation. Average latency will go down, and aggregate throughput will go up substantially. It’s counter-intuitive, but virtualization actually enables higher performance.
All these benefits came from playing games with the block address space. And we didn’t even talk about fancier data services, like the creation of snapshot instant copies of virtual disks, or data-at-rest encryption. The possibilities are nearly limitless.
I/O Virtualization
There is another way to think about block storage virtualization. Above, we were playing games virtualizing the block address. What if we play games some other way? We can also virtualize individual I/O requests.
What on earth does that mean? Here, you stop thinking so much about remapping blocks and think more about “How do I answer this read request?” and “How do I answer this write request?” This opens up different lines of thought, with different possibilities.
Instead of remapping pages of block addresses like a basic virtual memory system, we can lay data out any way we like in our implementation.
We can lay it out sequentially, like a log. That alone has positive performance implications for random write workloads.
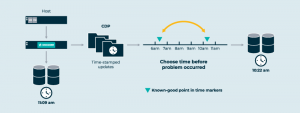
We could ignore the sequence and structure of individual I/O requests in that log, to focus on sequential layout leading to throughput performance. But if we preserve the sequence and structure of the individual requests, we build into the log a notion of time. Suddenly, we have a system that readily supports Continuous Data Protection (CDP), where I can instantly create an image of a virtual disk as it existed in the past. Of all the cool things you can do with software, time travel has got to be one of the coolest.
File Virtualization
What if we play with other access methods to virtualize other storage domains? Network file system protocols are another rich area for virtualization. Again, the access method suggests an API, and that gives us the framework for file virtualization.
File storage systems have file data and file metadata: the namespace hierarchy, folder names, file names, the file creation, access, and modification times. More things to play with! Let’s play games with data and with metadata.
Separation of Concerns
We can separate file metadata from file data. Why is that interesting? Two reasons: organization and performance.
A useful analogy here is the public library. If we think specifically of public libraries many years ago with their physical card catalog indexes, we’ll be able to see the separation and its implications more clearly. There’s a card catalog index (metadata), and there are books on shelves (data).
The card catalog is organized for fast and easy access. It’s in the front of the library, within easy reach. It’s organized by Subject, Author, and Title, for easy use. Relative to the pile of books, this index is pretty small. The index is organized and optimized according to user requirements.

The books can and should be organized separately according to completely different storage requirements. Rare books are in climate-controlled, expensive storage areas, with very little foot traffic. Paperbacks are in a different location, cheaper and more likely to be high traffic, along with periodicals. Larger folio and quarto volumes go on special shelving that accommodates their unusual size. Rarely accessed books can go off site.

This is so natural and obvious, we hardly think about it. But imagine if the card catalog were woven throughout the stacks, among the books and bookshelves, and you start to see how mixing metadata and data together might cause issues for applications accessing the storage systems.
Now consider a branch library. We can arrange for that branch to offer the entire global collection, even if very few of the books are stored there. We share the main card catalog with the branch, so that a user of the branch catalog sees the entire global collection (‘namespace’). A delivery system takes care of bringing books on demand. It’s obvious how separation of metadata from data makes this possible. (It’s also obvious how computer scientists can learn a lot from librarians, but that’s another story.)
By treating file metadata separately, we can build a global namespace that dissolves device-level boundaries. We can change the file metadata to reflect application or management requirements, allowing the file data can move on a different schedule, according to completely different requirements. We can share metadata to create cross-site collaborative universal namespaces. We can enhance the metadata with custom tags and values, increasing the usability (and value!) of all that file data.
Separation of file metadata from data enables high performance. The Parallel NFS standards define the contract between clients and servers, so that they can take advantage of the performance gains inherent in this separation of concerns.
File virtualization technology promises to be every bit as relevant and interesting as block storage virtualization has been for twenty years.
We hold these truths to be self-evident
The point is, the access method gives you a model for virtualization, which gives you a place to insert software and computing power, which gives you the power and potential for a Cambrian explosion of imaginative solutions to data and storage problems.
Virtualization systems come with a cost, but they seem always to prove their worth in compelling ways. It’s safe to say that virtualization is shown in many cases to be beneficial. Safe, but weak 🙂 . Working up a bit more nerve, we could say something stronger–that virtualization seems always to produce these benefits, like a law of nature.
It’s even more fun to say that the benefits of virtualization are axiomatic, not requiring proof, and that wherever you see hardware, you should break those eggs, because you’ll always get an omelet.
