Data is one thing that is constantly growing within an organization. And with it grow the storage requirements hand in hand. IT teams responsible for managing data storage are always facing the problem to run out of capacity soon and throwing hardware at the problem to meet business demand. Data deduplication and compression are popular techniques that help make storage capacity management more efficient.
To leverage capacity optimization through deduplication and compression, IT teams have two options of its implementation: either as inline or as post-processing approach. This blog will explore and compare the two implementations while also highlighting uses cases for when to use data deduplication solution.
A Quick Primer on Data Deduplication and Compression
![]() DEDUPLICATION eliminates to write duplicate blocks of data by replacing them with a pointer to their first iteration of the same dataset. Each incoming block of data is analyzed and assigned a unique hash value. If a new block getting written to disk has the same hash value as an existing block, it is replaced with an identifier that points to the existing data block. This saves the disk space that the redundant blocks of data would otherwise use in the storage pool. The benefits of deduplication are most abundant when there are multiple blocks of the same data, for example, redundancy found within snapshots or VDI images. Typically, primary storage will have lesser duplicate data, periodic archives will have comparatively more duplicate data, and repeated backups will have considerably higher duplicate data.
DEDUPLICATION eliminates to write duplicate blocks of data by replacing them with a pointer to their first iteration of the same dataset. Each incoming block of data is analyzed and assigned a unique hash value. If a new block getting written to disk has the same hash value as an existing block, it is replaced with an identifier that points to the existing data block. This saves the disk space that the redundant blocks of data would otherwise use in the storage pool. The benefits of deduplication are most abundant when there are multiple blocks of the same data, for example, redundancy found within snapshots or VDI images. Typically, primary storage will have lesser duplicate data, periodic archives will have comparatively more duplicate data, and repeated backups will have considerably higher duplicate data.
![]() COMPRESSION is an algorithmic process that shrinks the size of data by first finding identical data sequences appearing in a row and then saving only the first sequence and replacing the following identical sequences with the information on the number of times they appear in a row.
COMPRESSION is an algorithmic process that shrinks the size of data by first finding identical data sequences appearing in a row and then saving only the first sequence and replacing the following identical sequences with the information on the number of times they appear in a row.
By making data size smaller at a binary level, less disk space is consumed, and hence more data can be stored in the available capacity. Compression depends on the nature of the dataset itself – whether it is in a compressible format and how much of it can be compressed. Normally, duplicate character strings, for example, extra spaces are eliminated with the help of a compaction algorithm and then compressed data is stored in compression chunks within the storage device. This type of compression is lossless (does not cause any data loss).
With this understanding, let us now look at the two approaches that we wanted to compare in this blog: inline and post-process deduplication and compression.
Inline Deduplication and Compression
 Inline processing is a widely used method of implementing deduplication and compression wherein data reduction happens before the incoming data gets written to the storage media. The deduplication and compression tool is usually a software-defined storage (SDS) solution or a storage controller that controls where and how data gets placed. All the data traversing through the tool is scanned, deduplicated and compressed in real-time. Inline processing typically reduces the raw disk capacity needed in the system since the un-deduplicated and uncompressed dataset in its original size is never written to disk. Thus, the write operations executed are also correspondingly lower, reducing the wear on the disks.
Inline processing is a widely used method of implementing deduplication and compression wherein data reduction happens before the incoming data gets written to the storage media. The deduplication and compression tool is usually a software-defined storage (SDS) solution or a storage controller that controls where and how data gets placed. All the data traversing through the tool is scanned, deduplicated and compressed in real-time. Inline processing typically reduces the raw disk capacity needed in the system since the un-deduplicated and uncompressed dataset in its original size is never written to disk. Thus, the write operations executed are also correspondingly lower, reducing the wear on the disks.
Note: Inline deduplication is also known as source deduplication in the backup context.
Post-Process Deduplication and Compression
 Post-processing is the approach where the data first gets written to the storage media and then it is analyzed for duplication and compression opportunities. Because deduplication and compression are executed only after the data gets stored once on the storage device, there is as much initial capacity required as the raw data size (prior to data reduction). The capacity-optimized data is then saved back to the storage media with potentially lesser space requirements than before data reduction.
Post-processing is the approach where the data first gets written to the storage media and then it is analyzed for duplication and compression opportunities. Because deduplication and compression are executed only after the data gets stored once on the storage device, there is as much initial capacity required as the raw data size (prior to data reduction). The capacity-optimized data is then saved back to the storage media with potentially lesser space requirements than before data reduction.
Note: Post-process deduplication is also known as target deduplication in the backup context.

Difference between inline vs. post-process deduplication and compression
When to Use Which Capacity Optimization Approach
- When there are constraints to disk capacity allocation on the target device, it is preferable to go with inline processing as it only requires storage space for the deduped and compressed data and not for the full raw data.
- When performance needs to be ensured continually and there is uncertainty on the capacity optimization potential and how it could impact performance, post-processing would be a preferred approach. Since capacity optimization happens after data gets stored, there is not much performance impact when data gets written.
- When data to be written has an obvious greater potential for capacity optimization (for e.g., there is a lot redundant data to deduplicate, specific data types supporting higher compression rates), inline processing would yield higher space efficiency and likely even better storage performance as writes operations are minimized and wear on the disk is lowered accordingly. However this would require the storage/IT administrator understanding the nature of data being written and estimating the efficiency of data reduction beforehand.
- When you want to take control of when capacity optimization should happen, post-processing would be a better option as it can be scheduled for when there is not much application activity. This could also help avoid the risk of negative performance impact especially when there is peak load and application activity.
Factors Influencing Types of Deduplication Compression
While setting capacity saving goals for inline and post-processing data reduction approaches, you have to consider the below deterministic factors that impact the deduplication and compression efficiency ratios, which is instrumental in influencing storage performance positively or negatively:
- Type of data: The type of data plays a key role in determining how much it can be deduplicated or compressed. With databases, there is already some level of redundancy removal at the application level. So, databases may not yield high savings with deduplication and compression. Snapshots of operating system images (such as in a VDI environment) can be expected to deliver higher capacity optimization ratios.
- Rate of data changes: When fewer changes are made to the data, the easier and faster it is to perform deduplication and compression. Every change made to the data and saved to disk requires a separate cycle of examination to identify duplicate datasets and execute the compression algorithm. This will subsequently increase the overhead on the server.
- Data backup frequency: As discussed earlier, especially in the case of full backups, the greater the frequency of backup, the more redundant data is generated. This will result in greater space savings when deduped and compressed.
The efficiency of deduplication and compression can be measured as a ratio of the original raw data size versus the reduced size. For example, with a deduplication ratio of 10:1, 100 GB of raw data would require only 10 GB of storage capacity, resulting in 90% space savings. Higher the ratio, more the capacity savings. This depends on the capability of the software performing deduplication and compression and the other factors mentioned above.
DataCore SANsymphony software-defined block storage solution supports both inline and post-process deduplication and compression. Contact DataCore to learn more about SANsymphony and find out how to optimize storage capacity and maximize resource utilization.
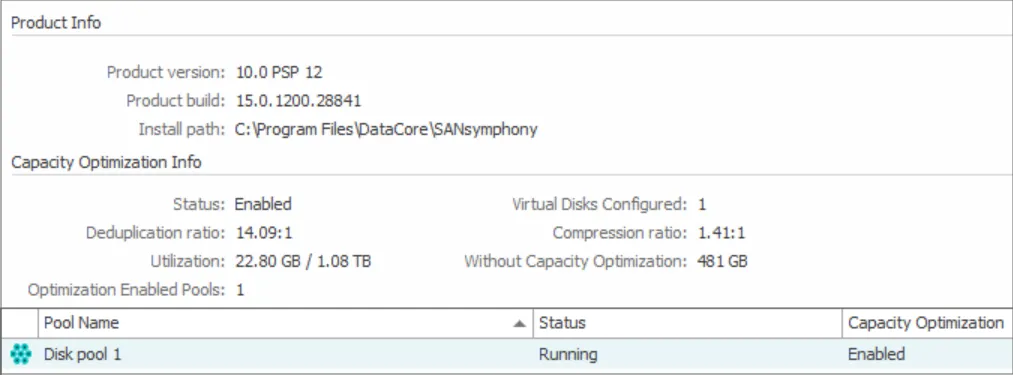
DataCore SANsymphony showing results of inline deduplication and compression
Keep in mind that storage efficiency directly translates to application performance and business productivity. Choosing the desired approach between inline and post-processing ultimately depends on the use cases for each organization and their infrastructure. Both approaches can also be used complementarily within the same storage environment (in distinct storage pools).
