From the Register Article by Chris Mellor: The SPC-1 benchmark is cobblers, thunders Oracle veep
DataCore Announcement:
DataCore Parallel Server Rockets Past All Competitors, Setting the New World Record for Storage Performance
Measured Results are Faster than the Previous Top Two Leaders Combined, yet Costs Only a Fraction of Their Price in Head-to-head Comparisons Validated by the Storage Performance Council; See Chart Below:
DataCore Announcement:
DataCore Parallel Server Rockets Past All Competitors, Setting the New World Record for Storage Performance
Measured Results are Faster than the Previous Top Two Leaders Combined, yet Costs Only a Fraction of Their Price in Head-to-head Comparisons Validated by the Storage Performance Council; See Chart Below:
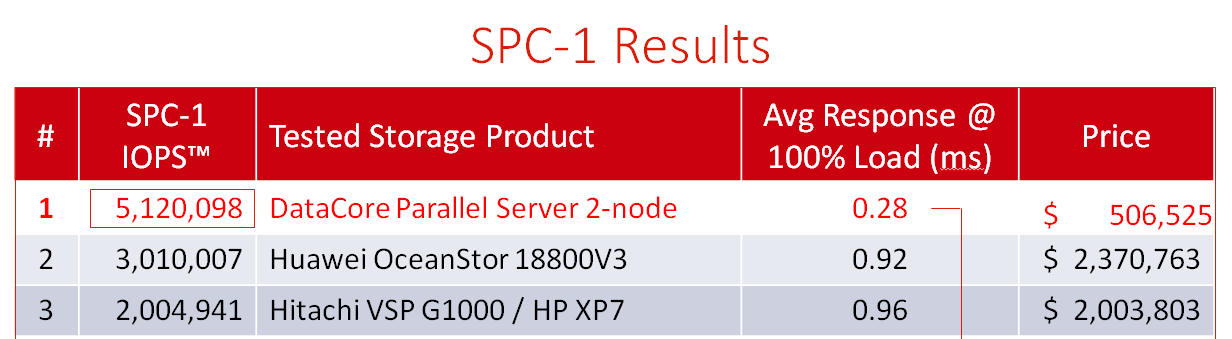
Comments from the original article: The DataCore SPC-1-topping benchmark has attracted attention, with some saying that it is artificial (read cache-centric) and unrealistic as the benchmark is not applicable to today’s workloads.
Oracle SVP Chuck Hollis told The Register: “The way [DataCore] can get such amazing IOPS on a SPC-1 is that they’re using an enormous amount of server cache.”
…In his view: “The trick is to size the capacity of the benchmark so everything fits in memory. The SPC-1 rules allow this, as long as the data is recoverable after a power outage. Unfortunately, the SPC-1 hasn’t been updated in a long, long time. So, all congrats to DataCore (or whoever) who is able to figure out how to fit an appropriately sized SPC-1 workload into cache.”
But, in his opinion, “we’re not really talking about a storage benchmark any more, we’re really talking about a memory benchmark. Whether that is relevant or not I’ll leave to others to debate.”
DataCore’s response … Sour grapes
Ziya Aral, DataCore’s chairman, has a different view, which we present in at length as we reckon it is important to understand his, as well as DataCore’s, point of view.
“Mr. Hollis’ comments are odd coming from a company which has spent so much effort on in-memory databases. Unfortunately, they fall into the category of ‘sour grapes’.”
“The SPC-1 does not specify the size of the database which may be run and this makes the discussion around ‘enormous cache’, etc. moot,” continued Aral. “The benchmark has always been able to fit inside the cache of the storage server at any given point, simply by making the database small enough. Several all-cache systems have been benchmarked over the years, going back over a decade and reaching almost to the present day.”
“Conversely, ‘large caches’ have been an attribute of most recent SPC-1 submissions. I think Huawei used 4TB of DRAM cache and Hitachi used 2TB. TB caches have become typical as DRAM densities have evolved. In some cases, this has been supplemented by ‘fast flash’, also serving in a caching role.”
Aral continued:
In none of the examples above were vendors able to produce results similar to DataCore’s, either in absolute or relative terms. If Mr. Hollis were right, it should be possible for any number of vendors to duplicate DataCore’s results. More, it should not have waited for DataCore to implement such an obvious strategy given the competitive significance of SPC-1. We welcome such an attempt by other vendors.
“So too with ‘tuning tricks,’” he went on. “One advantage of the SPC-1 is that it has been run so long by so many vendors and with so much intensity that very few such “tricks” remain undiscovered. There is no secret to DataCore’s results and no reason to try guess how they came about. DRAM is very important but it is not the magnitude of the memory array so much as the bandwidth to it.”
Symmetric multi-processing
Aral also says SMP is a crucial aspect of DataCore’s technology concerning memory array bandwidth, explaining this at length:
As multi-core CPUs have evolved through several iterations, their architecture has been simplified to yield a NUMA per socket, a private DRAM array per NUMA and inter-NUMA links fast enough to approach uniform access shared memory for many applications. At the same time, bandwidth to the DRAMs has grown dramatically, from the current four channels to DRAM, to six in the next iteration.
The above has made Symmetrical Multi-Processing or SMP, practical again. SMP was always the most general and, in most ways, the most efficient of the various parallel processing techniques to be employed. It was ultimately defeated nearly 20 years ago by the application of Moore’s Law – it became impossible to iterate SMP generations as qucikly as uniprocessors were advancing.
DataCore is the first recent practitioner of the Science/Art to put SMP to work… in our case with Parallel I/O. In DataCore’s world record SPC-1 run, we use two small systems but no less than 72 cores organized as 144 usable logical CPUs. The DRAM serves as a large speed matching buffer and share
d memory pool, most important because it brings a large number of those CPUs to ground. The numbers are impressive but I assure Mr. Hollis that there is a long way to go.
d memory pool, most important because it brings a large number of those CPUs to ground. The numbers are impressive but I assure Mr. Hollis that there is a long way to go.
DataCore likes SPC-1. It generates a reasonable workload and simulates a virtual machine environment so common today. But, Mr. Hollis would be mistaken in believing that the DataCore approach is confined to this segment. The next big focus of our work will be on, analytics which is properly on the other end of this workload spectrum. We expect to yield a similar result in an entirely dissimilar environment.
The irony in Mr. Hollis’ comments is that Oracle was an early pioneer and practitioner of SMP programming and made important contributions in that area.
…
DRAM usage
DataCore’s Eric Wendel, Director for Technical Ecosystem Development, added this fascinating fact: “We actually only used 1.25TB (per server node) for the DRAM (2.5TB total for both nodes) to get 5.1 million IOPS, while Huawei used 4.0TB [in total] to get 3 million IOPS.”
Although 1.536TB of memory was fitted to each server only 1.25TB was actually configured for DataCore’s Parallel Server (See the full disclosure report) which means DataCore used 1.5TB of DRAM in total for 5 million IOPS compared to Huawei’s 4TB for 3 million IOPS…
