Il a fallu longtemps pour que la technologie se développe, que le marché en comprenne l’intérêt et que les organisations y testent et déploient des applications.
Cette année, toutefois, les containers sont devenus une réalité concrète. Nous avons vu des chiffres d’adoption qui montrent que la technologie est passée de « intéressante » à « largement déployée en production ». Permettez-moi de donner quelques précisions :
- Lors d’une série d’entretiens réalisés dans le courant de l’année avec des clients (directeurs/vice-présidents de grandes entreprises dans le monde entier), nous avons remarqué que 50 % d’entre eux possédaient déjà des applications basées sur des containers en production.
- Une enquête auprès des utilisateurs de VMUG (environ 300 réponses de spécialistes du stockage dans des entreprises de taille moyenne) a montré que 45 % d’entre eux déployaient désormais davantage d’applications en containers.
- Notre propre conseil consultatif de revendeurs a indiqué que 33 % d’entre eux utilisaient déjà des applications en containers en production et que 67 % étudiaient la question.
La complexité est le plus grand obstacle à l’adoption
Les containers, Kubernetes et toutes les technologies associées sont encore des nouveautés pour la plupart des organisations. Il n’existe pas de bassin de talents disponibles dans lequel puiser. De nombreux aspects tels que l’évolutivité, la surveillance, la sécurité, le stockage persistant et la disponibilité nécessitent une nouvelle réflexion et de nouveaux outils. Comme pour tout marché émergent à fort potentiel, celui-ci présente de nombreuses alternatives et oblige à prendre de nombreuses décisions architecturales.
La complexité de la situation représente la principale difficulté pour les organisations qui exécutent des applications en containers. Cette complexité est même jugée plus critique que d’autres critères, comme les transformations culturelles, la sécurité ou le stockage, comme le montre le tableau ci-dessous tiré d’une enquête réalisée par la Cloud Native Computing Foundation (CNCF).
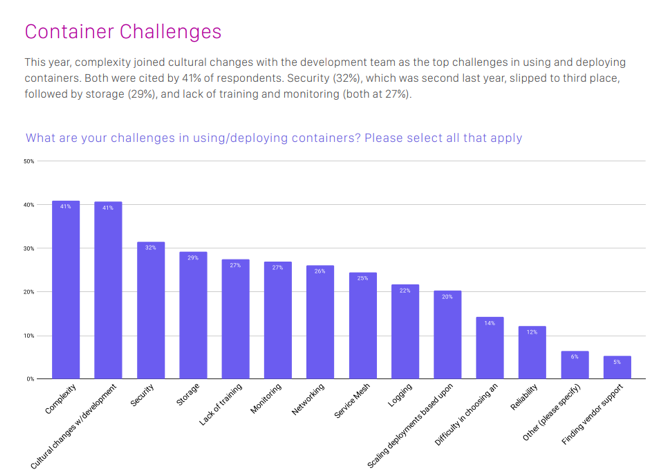
Source : CNCF_Survey_Report_2020.pdf
La complexité pose également un autre problème, celui de la pénurie de compétences. Un récent article a publié les résultats d’une enquête réalisée par Canonical selon laquelle plus de 50 % des réponses (sur plus d’un millier) citaient l’insuffisance de compétences internes comme le plus grand obstacle à l’utilisation de Kubernetes et des containers.
Mais voici qu’arrive OpenEBS, la plate-forme leader du stockage natif en containers.
OpenEBS est un projet open source conçu pour simplifier le déploiement de charges de travail stateful dans Kubernetes nécessitant un stockage en container fiable et rapide (container-attached storage, CAS). Cette approche offre plusieurs avantages déterminants :
- Chaque charge de travail possède son propre contrôleur de stockage dans la pile de containers, ce qui lui confère une portabilité et une indépendance matérielle totales. Les applications s’exécutent partout de la même manière, que ce soit sur site, dans un cloud public ou dans un environnement hybride.
- Déploiement immédiat : il suffit de quelques secondes pour déployer une nouvelle charge de travail, y compris la capacité de créer des clones et des snapshots.
- Grâce au Thin Provisioning, à la couverture des zones de disponibilité et à la simplicité de gestion, les entreprises économisent de l’argent et réduisent leur charge opérationnelle, d’autant que l’intelligence du stockage se trouve dans Kubernetes même.
OpenEBS est sorti sous la version 1.0 à la mi-2018. Peu de temps après, la solution est devenue un projet du CNCF. Le CNCF est l’organisme communautaire qui soutient des projets comme Kubernetes, fluentd, containerd, vitess, etcd, helm, jaeger, Prometheus et bien d’autres. Le fait d’être un projet CNCF est un gage de bonne gouvernance du projet par la collectivité.
Parmi les avantages qu’offre OpenEBS, on peut citer le provisionnement automatisé et le stockage d’applications stateful inter-cloud, les sauvegardes et la prise en charge de plusieurs moteurs et modes de stockage pour donner à chaque application des capacités optimales. Avec la version 3.0 publiée en septembre, OpenEBS est aujourd’hui une plate-forme stable et plus conviviale, avec réplication synchrone, de meilleures performances, un tableau de bord amélioré et un fournisseur NFS dynamique.
Tout cela en a fait la norme de fait pour le stockage en containers. Son adoption par la communauté et les contributions des membres font qu’OpenEBS est l’un des projets open source qui connaissent la croissance la plus rapide. C’est ce que montre le tableau ci-dessous, qui en compare les téléchargements au cours des quatre premières années suivant le lancement à ceux de MongoDB et de Confluent.
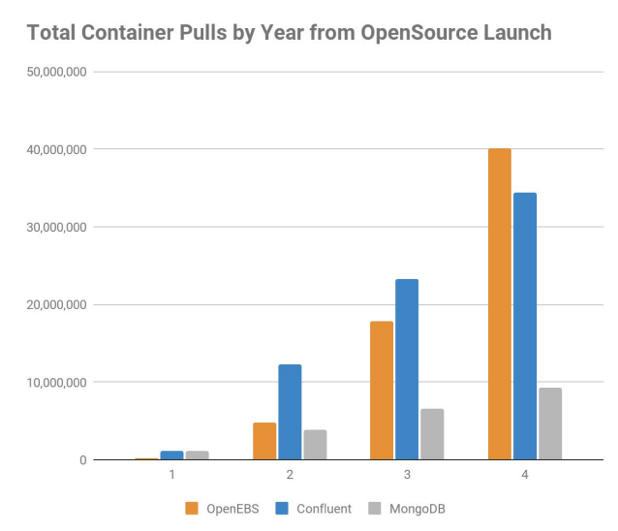
Téléchargements de containers par an
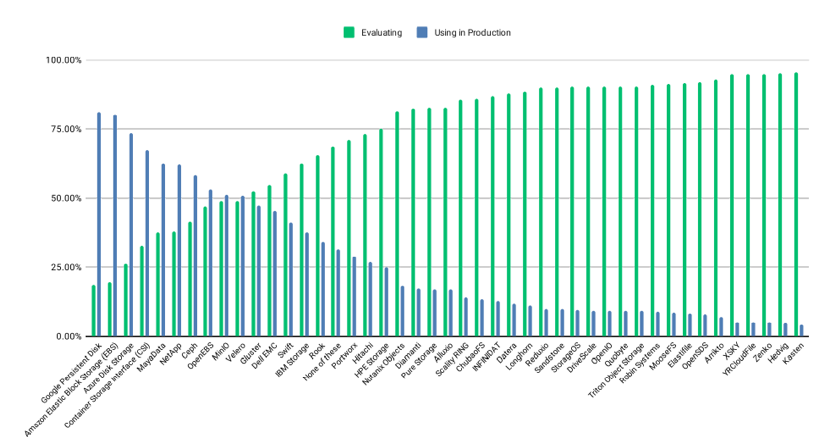
L’enquête CNCF déjà citée montre OpenEBS et MayaData (la société qui produit OpenEBS) en tête des autres solutions CAS, juste derrière les plateformes de type hyperscaler et les interfaces standard comme Container Storage Interface (CSI). En combinant les réponses pour MayaData et OpenEBS, on peut voir qu’environ 65 % des utilisateurs utilisent OpenEBS/MayaData en production.
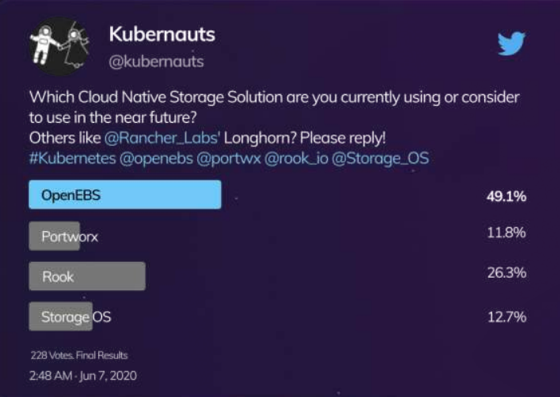
Une autre étude informelle réalisée il y a un peu plus d’un an par @kubernauts sur Twitter a montré que 49 % des utilisateurs utilisaient OpenEBS, loin devant Rook, StorageOS et Portworx.
MayaData, la société qui produit OpenEBS
Rien de tout cela n’aurait été possible sans MayaData, l’acteur qui a le plus contribué à OpenEBS, et sans le travail acharné de toute son équipe, notamment Kieran Mova, son architecte en chef. Ces quatre dernières années, tous ont consacré leur temps et leur énergie à faire vivre une communauté et œuvrer à la réussite d’OpenEBS.
Il y a trois ans, nous avons compris que les containers allaient devenir la norme et nous avons décidé d’investir dans la création d’une solution de containers. En janvier dernier, DataCore et MayaData ont formé un partenariat conjoint qui portait sur des investissements, des apports de propriété intellectuelle, le transfert de notre équipe de containers et des efforts de collaboration. Nous nous sommes alors rendu compte qu’un marché était en formation et que nous aurions plus de chances de réussir en nous associant à une entreprise en plein essor et qui participait déjà activement à la communauté.
Un exemple de ce partenariat est l’utilisation du savoir-faire légendaire de DataCore en matière de performances, en partenariat avec Intel, pour optimiser les performances d’OpenEBS avec les lecteurs NVMe. On peut en voir le résultat dans le tableau de référence ci-dessous, qui montre mieux que des mots les avantages offerts en matière de performances.
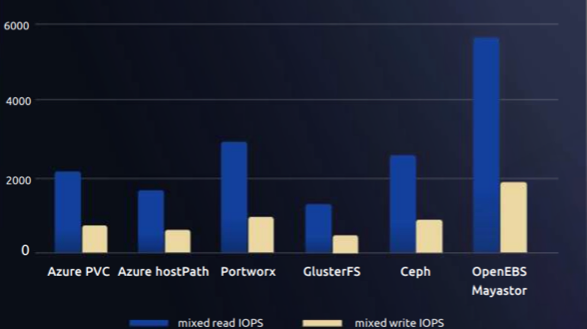
Aujourd’hui, compte tenu de l’élan dont bénéficie OpenEBS et de la maturité de la technologie des containers, DataCore fait l’acquisition de MayaData. Cette acquisition montre qu’il est devenu nécessaire d’accélérer le développement de la technologie de MayaData pour en faire une offre commerciale sérieuse, proposée par un fournisseur capable d’offrir le support, les ressources et le savoir-faire qui pourront favoriser l’adoption des charges de travail d’entreprise, tout en restant fortement impliqué envers la communauté.
Maintenant que les containers ont atteint leur masse critique, les organisations déployant de vraies charges de travail sur Kubernetes rechercheront des solutions qui présentent non seulement des mérites techniques crédibles, mais qui offrent aussi la fiabilité et le soutien dont elles ont besoin pour s’engager dans cette technologie.
DataCore fournira cette garantie de stabilité, le support technique nécessaire et la fiabilité induite par le fait de travailler avec une entreprise leader des technologies de stockage. MayaData continuera en outre à voir ses performances améliorées (Intel assure que MayaData est déjà la solution de stockage en containers la plus rapide du marché. Cet article de Blocks et Files vous en dit davantage). Elle bénéficiera par ailleurs de capacités de portabilité, de simplicité, de disponibilité, de sécurité des données, etc.
Cette analyse Industry Snapshot de The Evaluator Group complète le tableau des annonces d’aujourd’hui, avec notamment une feuille de route pour l’avenir et des explications sur la façon dont tout cela s’intègre dans le reste du secteur.
Que réserve l’avenir ?
Peu de bouleversements technologiques ont été aussi fondamentaux que ceux provoqués aujourd’hui sous nos yeux par les containers. Pour ceux d’entre nous qui ont eu l’occasion de travailler avec des containers, il est évident que ceux-ci joueront à l’avenir un rôle majeur dans le fonctionnement des charges de travail. Pouvoir assister à cette évolution et y participer activement est véritablement passionnant.
Aujourd’hui est le premier jour où DataCore + MayaData se présentent sous la forme d’une même et unique entreprise. Pour autant, nous avons déjà travaillé pour créer une feuille de route améliorée et un plan visant à faire d’OpenEBS une plus grande réussite encore. Dans le même temps, nous continuerons d’améliorer les capacités des containers dans le reste de la gamme en mettant à jour l’interface CSI et en créant davantage de capacités natives pour les containers.
